Revolutionizing Archival Document Processing with AI: Enhancing Degraded Historical Document Images
In recent years, the rapid advancements in Natural Language Processing (NLP) and the development of Large Language Models (LLMs) have opened new avenues for automating complex tasks across various industries. Archives, traditionally known for labor-intensive processes, are among the fields set to benefit significantly from these technologies. Historically, managing and interpreting archival documents has required manual sorting, reading, and interpreting—often under the added challenge of working with degraded or damaged materials.
However, modern AI technologies are now providing innovative solutions to overcome these obstacles. The Rényi AI group, in collaboration with the the Historical Archives of the Hungarian State Security and the National Archives of Hungary, is harnessing cutting-edge AI tools to revolutionize archival work. By implementing techniques such as Retrieval-Augmented Generation (RAG) and automated Sensitive Data Removal, researchers and the general public alike are gaining unprecedented access to historical records, all while ensuring the secure handling of confidential information.
The Unique Challenges of Archival Documents
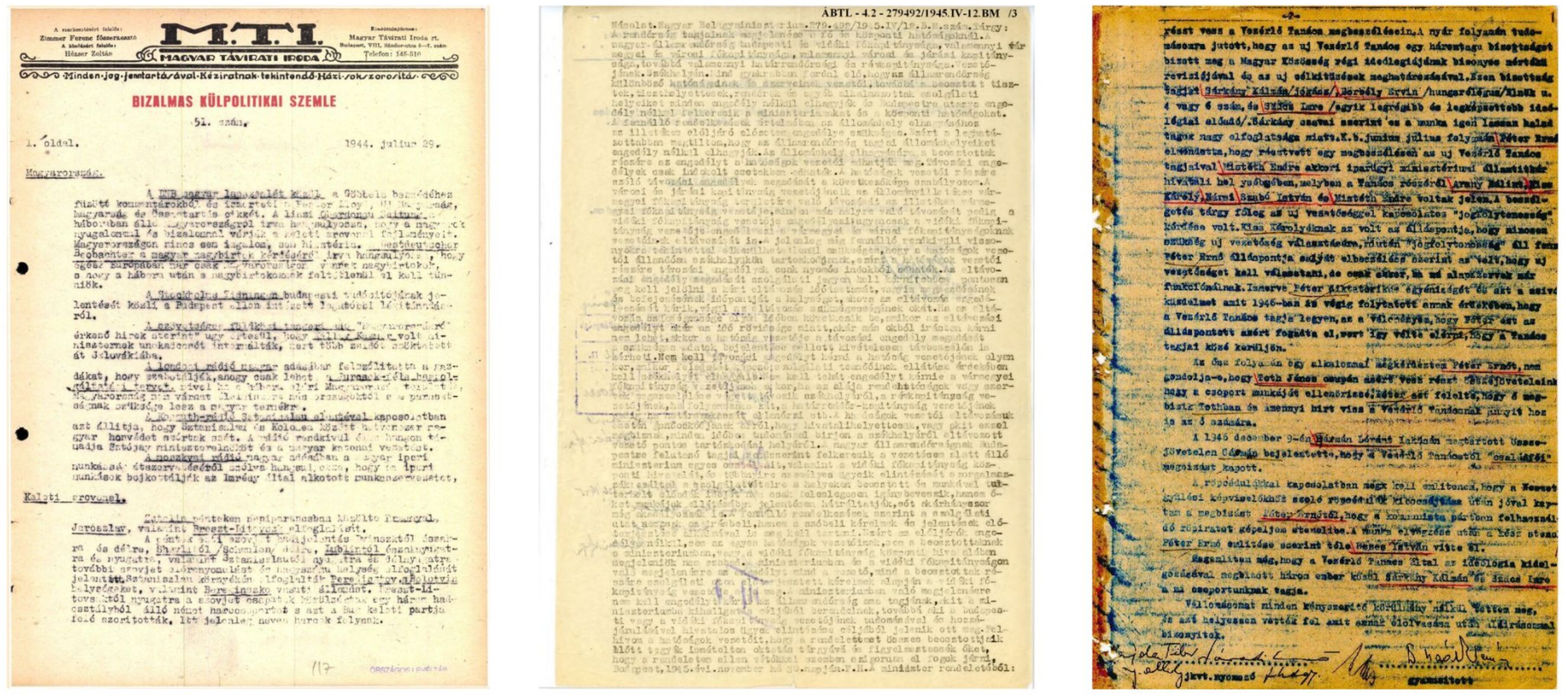
Despite the transformative potential of AI in the archival domain, processing historical documents presents unique challenges. Unlike modern, digitally-born documents, archival records often suffer from significant degradation due to factors like age, poor storage conditions, and manual annotations (see Figure 1). Issues like faded text, ink bleed-through, stains, and handwritten notes complicate traditional Optical Character Recognition (OCR) methods, making accurate text extraction a daunting task.
State-of-the-art OCR solutions underperform on degraded documents
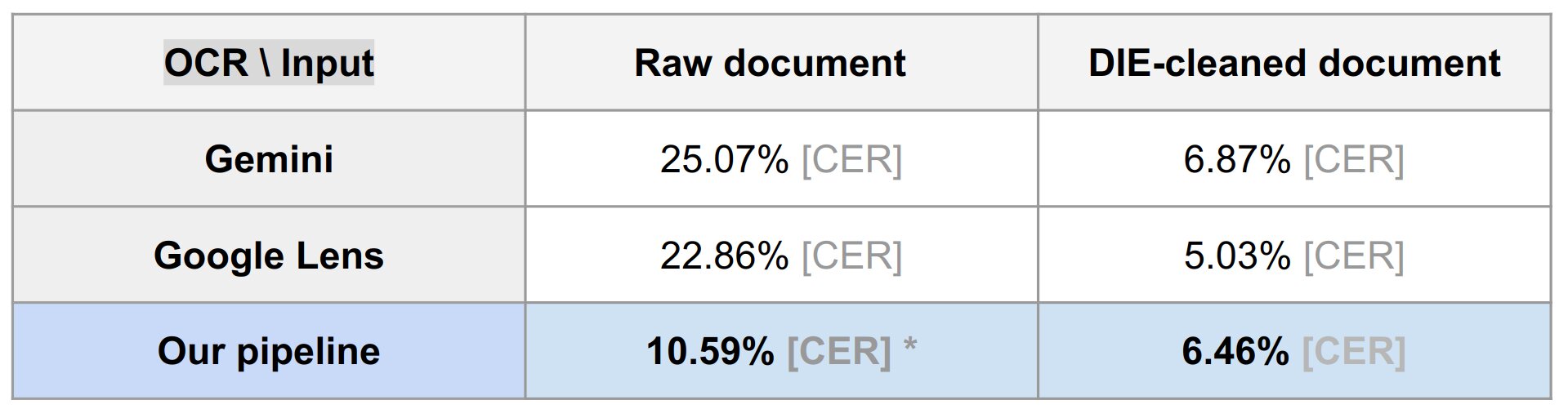
Off-the-shelf OCR solutions perform exceptionally well on clean, born-digital documents but fall short when applied to degraded archival pages. To illustrate this, we tested top OCR tools, including Gemini and Google Lens, on a severely damaged archival document (see Figure 2). Both systems struggled with accuracy, resulting in character error rates (CER) between 23-25% and word error rates (WER) exceeding 50%. These findings emphasize the limitations of current OCR technologies when applied to historical materials.

Enhancing OCR Performance with Document Image Enhancement (DIE)
As the previous demonstration shows, traditional OCR systems often struggle with noisy archival documents. This challenge is not unique to historical records; a broader field known as Document Image Enhancement (DIE) has emerged to address such issues. DIE focuses on improving the visual quality of document images, particularly for the purpose of optimizing OCR performance. By reducing various forms of noise and enhancing text visibility, DIE significantly boosts the accuracy of text detection and text recognition systems.
Recognizing the limitations of existing OCR tools when applied to historical documents, we developed a specialized DIE model. This custom solution was designed to address the specific challenges posed by degraded archival materials, such as faded text, stains, and other imperfections that hinder traditional OCR systems. By focusing on image quality enhancement, our DIE model bridges the gap between standard OCR tools and the unique demands of processing historical records.
Our solution
Our solution is built around a deep learning-based DIE model, utilizing a convolutional U-Net architecture, which is particularly well-suited for tasks like noise removal while retaining the original image structure. The U-Net’s design, especially its use of skip connections, plays a crucial role in this process. Skip connections allow the model to combine low-level image details from earlier layers with more abstract features learned in deeper layers, ensuring that important information, such as fine text details, is preserved while noise is effectively removed.
By training the model with pairs of degraded archival images and their corresponding clean versions, the model learns to recognize and remove complex noise patterns. Thanks to the strong generalization capabilities of deep learning, once the model is trained on a rich and representative set of examples from aged documents, it can be effectively applied across different archives. This modular solution integrates seamlessly as a preprocessing step, improving document quality without requiring any changes to the existing OCR pipeline.
Before-and-After Examples of Document Image Enhancement
Here, we showcase two examples of documents with severely degraded text. After applying our DIE model, we successfully remove most of the visual noise—including scribbles, transparency issues, blurring, and background patterns—while preserving the legibility of the text. This enhancement not only enables far more accurate text extraction but also significantly improves the overall efficiency of the text detection process, making it easier to handle even the most challenging archival materials.

Hugging Face Demo of our Document Image Enhancement model
We have developed an interactive online demo for our Document Image Enhancement (DIE) model, hosted on Hugging Face, where users can experience the power of AI-driven restoration for degraded documents firsthand. The demo allows anyone to upload their own challenging document images and observe how our model enhances them by mitigating issues like faded text, ink bleed-through, and background noise. For those without a document to test, we’ve included several default examples showcasing the model’s capabilities. While the demo currently operates on CPU, not GPU, it provides an accessible and intuitive way for researchers, archivists, and the general public to explore our state-of-the-art solution for degraded document processing.
Demonstrating Enhanced OCR Performance with DIE-Processed Images
When we integrated our DIE model as a preprocessing step within the OCR frameworks, the character error rate (CER) decreased by approximately 20%, bringing it down to an impressive 5-6%. This substantial improvement underscores the effectiveness of our DIE model in boosting OCR performance on degraded archival documents, enabling more accurate and reliable text recognition even in challenging conditions.

Tackling the Data Challenge: our Synthetic Data Generation framework
After demonstrating the capabilities and effectiveness of deep learning-based DIE models, it’s important to address a critical challenge for these types of machine learning solutions: data. As we’ve highlighted before, the quality of data fundamentally affects the performance of any model. But in the case of degraded archival documents, how can we generate the right kind of data to train our models effectively?
There are two main approaches to this challenge: human labeling and synthetic labeling. Human labeling, while accurate, is both costly and extremely difficult for the DIE task due to the complexity and variability of degradation types found in historical records. On the other hand, synthetic labeling offers a more scalable and efficient alternative, provided that we can capture the wide range of degradation patterns that exist in real-world archival documents.
To address this, we developed a synthetic data generation framework. Our framework implements over 30 distinct domain-specific noise types—such as ink bleed-through, scribbles, and fading—to create progressively degraded document images (see Figure 5).

These synthetic images closely replicate the diverse challenges found in historical records (see Figure 6), forming a rich dataset for training our DIE models. Additionally, our framework is designed to be adaptable: when we encounter poor model performance on certain subsets of documents, we incrementally add new types of noise to further refine the model’s ability to generalize across various degradation types. This approach ensures continuous improvement in our ability to clean up and enhance archival materials.

Fine-Tuning OCR Models Directly on the Degraded Domain Using Synthetic Data Generation
The primary goal of our DIE model is to improve OCR quality by addressing domain-specific degradation and noise in archival materials. However, deep learning-based OCR models can also be trained directly on noisy documents without requiring image cleaning. Our Synthetic Data Generation framework not only produces clean versions of degraded document images but also generates the corresponding text, allowing us to train OCR models in a highly supervised manner.
For our OCR needs, we trained a state-of-the-art architecture called TrOCR, a transformer-based model specifically designed to process text lines. One key advantage of training our own local OCR model is that it allows us to handle private documents securely, without relying on external services.
Our evaluation (see Figure 7) demonstrated that, on noisy, raw document images, our model outperformed existing state-of-the-art OCR solutions that were trained on general domains. Additionally, when we applied our DIE model to preprocess the images, we achieved performance comparable to the best OCR systems, highlighting the effectiveness of both our synthetic data generation and document enhancement techniques.
However, these results do not mean that we cannot use our DIE model effectively. Beyond improving OCR accuracy, the use of the DIE model also benefits other tasks, such as text detection, by making the underlying content more accessible and easier to process.
The Future of Archival Document Processing
The tools and methods introduced in this blog post lay the groundwork for future advancements in archival document processing. By leveraging our Synthetic Data Generation framework, we can train a customized Layout Detection model specifically tailored to handle complex documents with challenging layouts, such as those containing tables.
With enhanced text quality, various downstream tasks can be implemented to improve daily archival workflows. This will not only dramatically reduce manual labor—eliminating bottlenecks like time-consuming processes—but also enable archives to scale up their digitization efforts. Furthermore, integrating NLP-based tools, such as LLMs and RAG systems, will allow researchers to more easily search, analyze, and extract valuable insights from these records. This will streamline both academic and historical research, opening new possibilities for exploring historical data.